I recently read the great book Fooled By Randomness by Nicholas Nassim Taleb. There is a nice illustrative example in there on the scaling property of distributions across different time scales. The example is formulated as the hypothetical example of a dentist who has set up a home trading environment and started to invest in some assets (say stocks). The dentist has access to real-time market data and thus can check in on their current investment portfolio valuation at any point in time.
The investment portfolio has an expected annual return of 15% and volatility of 15%. The assertion in the book is that the more frequently the dentist appears to check the performance of the portfolio, the worse it will seem to perform(see the table below). The question is why, as at first glance it appears counter-intuitive.
The answer is as follows – if we assume a normal distribution for the portfolio returns, the parameters above define a distribution with a mean of 15% and a standard deviation of 10%, .i.e. $\mathcal{N}(0.15, 0.10)$
We can represent this in R as follows:
mu <- .15 sigma <- .1 x <- seq(-2,2,.01) y <- dnorm(x,mean = mu, sd = sigma) qplot(x,y) + geom_line() + geom_vline(aes(xintercept=mu),color='red') + geom_vline(aes(xintercept=c(mu-sigma,mu+sigma)),linetype=2)
The graph shows the implied distribution plus the mean (red line) and standard deviation (dashed lines)
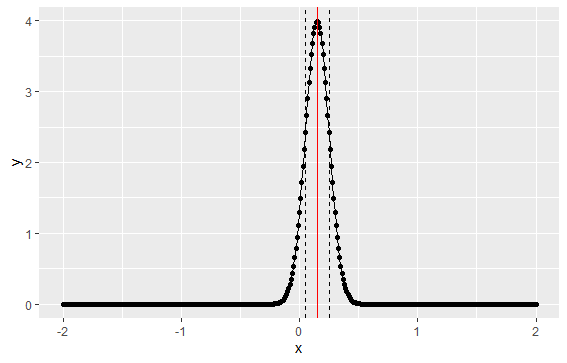
Under this implied distribution, 2 standard deviations (or 95%) results in a return spanning -5% to +35%:
mu + 2*sigma [1] 0.35 mu - 2 *sigma [1] -0.05
Looking again at the table from the book above – if we calculate success as a return > 0, then we can calculate the probability of success for the distribution above. We can calculate this using the the normal cumulative distribution – which is basically the the sum of the area under the normal curve above – and find out what this value is for 0.
In R, pnorm() gives us the area under the curve. Actually it gives us $P(X<=0)$ so in order to calculate success $(P(X>0))$ we need to calculate the inverse probability:
1-pnorm(0,mean = mu, sd=sigma) [1] 0.9331928
So the probability of success over one year is 93%, which matches the table above.
Now what happens if the dentist checks their portfolio more frequently – i.e. what does the return look like over 1 quarter as opposed to 1 year? In order to calculate this, we need to adjust the parameters to scale it to a quarterly distribution. So $\mu_Q = \frac{\mu_A}{4}$ and $\sigma_Q = \frac{\sigma_A}{\sqrt{4}}$, i.e. the mean will be divided by 4 to convert to quarters, and the standard deviation will be divided by the square root of 4, as volatility scales with the square root of time.
1-pnorm(0,mean = mu/4, sd=sigma/sqrt(4)) [1] 0.7733726
So we can see that moving from an annual to a quarterly distribution has lowered the probability of success from 93% to 77%
Similarly if we now move from quarterly to monthly, the distribution will be a $ \mathcal{N}{\frac{\mu_A}{12}, \frac{\sigma_A}{\sqrt{12}}}$ distribution:
1-pnorm(0,mu/12, sigma/sqrt(12)) [1] 0.6674972
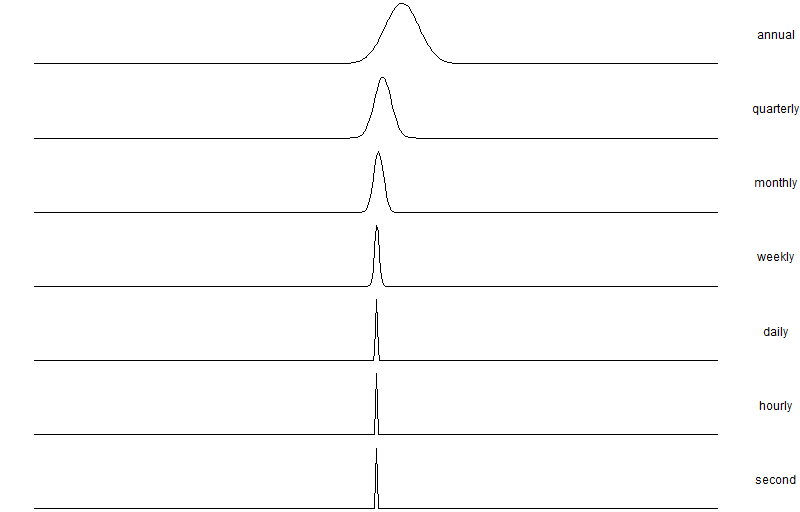
Which is roughly 67%. Further, we can tabulate the various scaling factors all the way from 1 (annual) to 31536000 (1-second horizon) and calculate the probability of success for each time horizon. We can see the success probability diminish from 93% down to 50% at a one-second resolution.
factors <- c(1,4,12,52,365,8760,31536000) sapply(factors, function(x) success(mu, sigma, x)) [1] 0.9331928 0.7733726 0.6674972 0.5823904 0.5312902 0.5063934 0.5001066
To make it clearer we can calculate the density of each distribution and plot it:
mu <- 0.15
sigma <- 0.1
x <- seq(-2,2,.01)
factors <- c(1,4,12,52,365,8760,31536000)
names <- c('x','annual','quarterly','monthly','weekly','daily','hourly','second')
# Calculate the density for the distribution at each timescale
tab <- data.frame(x=x)
for (f in seq_along(factors)) {
tab <- cbind(tab, dnorm(x, mu/factors[f], sd=sigma/sqrt(factors[f])))
}
# Plot each density in a separate panel
colnames(tab) <- names
ggplot(melt(tab,id.vars = 'x'), aes(x=x)) + geom_line(aes(y=value)) + facet_grid(variable~.,scales = 'free') + xlab('') + ylab('') + theme_void() + theme(strip.text.y = element_text(angle = 0))